共分散構造分析(SEM)
1. ロジックを科学的に検証
多くのマーケティング担当者は「自社の商品が売れていない」「他社の商品が売れている」などの場合に、その原因をロジックとして整理し、それをツリーなどの形状にまとめあげたことがあるはずです。(モノが売れる仕組みは通常それほど単純なものではないため、時にそのようなロジックはさまざまな要因を含んだ複雑なものになってしまうことがあります。)
しかし、そのようにして組み立てたロジックは1つの仮説に過ぎません。企業の意思決定を促すには、組み立てた仮説を客観的なデータをもとに検証する必要があります。従来の分析では「AならばBである」というシンプルなロジックを検証することは可能でしたが、さらに複雑な要因を持ったロジック、例えば「Aの原因としてBとCの2つがある。BはさらにDとEに影響し、CはFとGに影響する。さらにFとGがCより影響を与えられる度合いには男女間で差がある」といった複雑な関係を検証したい場合には、従来の分析では、分析を何度も繰り返さなければならず、統計的にみて誤差が蓄積するなど不十分な面が多々ありました。
第2世代の多変量解析と呼ばれる共分散構造分析※1(構造方程式モデリング、SEM/Structural Equation Modeling)の多重指標モデルを利用すると、先ほどの例のような関係性を、一度の分析で数値化して求めることができる上に、仮説ロジックを全体評価し、統計的な検証が行えます。
※1.共分散構造分析と呼ばれる理由は、「観測変数間の共分散の構造」を分析することで、直接観測できない潜在変数を導入し、因果関係の構造を分析する方法であるため。
2. 共分散構造分析(SEM)・多重指標モデル実例
2-1. 仮説のモデル化
下記のような課題の解決を例に、共分散構造分析の多重指標モデルによって実際に分析を進めながら、共分散構造分析・多重指標モデルとはどのようなものかについて解説します。
課題:下記の仮説を順次検証していくこと
- 仮説1. ダイエット飲料の魅力は、味の好ましさとダイエット効果と関係性がある
- 仮説2. 1の仮説に加え、CMをよく見て、良いイメージを持っている人ほど味の好ましさやダイエット効果が高いと答える
- 仮説3. CM効果とダイエット効果や味の良さとの関係性はブランドごとに異なる
共分散構造分析の多重指標モデルを用いてモデルの吟味やロジックの検証を行う場合には、まずそのモデルやロジックをパス図にする必要があります。今回の課題の仮説1、2をパス図にすると図1のようになります。
矢印は、原因の変数から結果の変数に向かって引きます。この矢印をパスと呼びます。また、赤い円は誤差を表しています。(その他記号の説明は図2)
このパス図に示したような仮説モデルを共分散構造分析にかけると、次のようなアウトプットが得られます。
- それぞれのパスの値を表すパス係数
- モデルがどれほどデータと矛盾していないかを示すモデル適合度
これらのアウトプットからモデルのあてはまりや、それぞれの変数間の関係の強弱をみることができるのです。
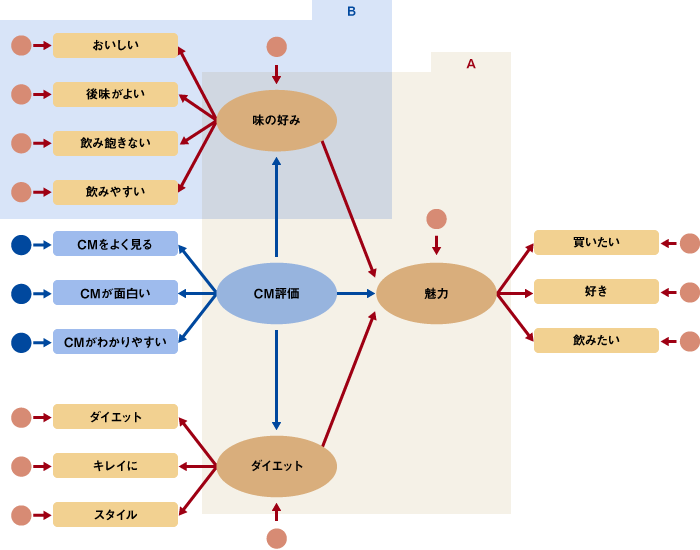
図1 仮説1、2をまとめたパス図

図2 パス図の読み方
このパス図を部分的に分解して図の読み方を解説していきましょう。
2-2. 潜在変数(因子)間の関係分析
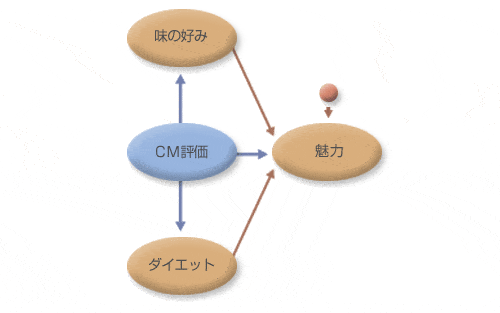
図3 図1のAを拡大した図
図3は図1のAの部分を拡大したものです。
まず、楕円の部分に注目してください。「味が好みであると答えた人は、商品を魅力的であると答えている」という部分を示すのが、味の好みから魅力に向けて引いた矢印=パスです。また、「ダイエット効果感があると答えた人もまた、商品を魅力的であると答える」という部分を示すのが、ダイエットから魅力に向けて引いたパスです。この「味の好み」「ダイエット」「魅力」の3つの変数間の関係は、味の好みとダイエットを説明変数(独立変数)にし、魅力を目的変数(従属変数)とする従来の重回帰分析と同じです。ですから、説明変数である味の好みとダイエットの説明力を求めることができます。しかし、この図3に示した仮説では「CM評価」も含まれます。CM評価が高い人は、「味の好ましさ」や「ダイエット効果」も高く、商品を「魅力的」である、とも答えていると仮定しています。重回帰分析の言葉でいえば、説明変数の間に因果関係があることになり、1つの重回帰分析のモデルでは分析できません。
共分散構造分析を用いると、このようなモデルでも1度の分析で数値化することができ、統計的にも誤差を蓄積することなく正しく解を求めることができます。また、目的変数が複数あり、階層性があるような複雑な仮説モデル構築ができ、従来の回帰分析と比べ大幅に自由な分析・検証を行うことができます。
複雑なモデルは我田引水になりがちですが、共分散構造分析の場合には適合度指標が複数提案されていますので、データから見てモデルの矛盾が大きすぎないか、調べることができます。
2-3. 潜在変数(因子)と観測変数
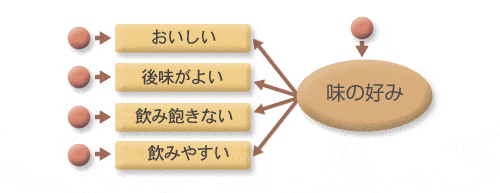
図4 図1のBを拡大した図
図4は図1のBの部分を拡大したものです。
ここには「おいしい」や「後味がよい」など、元の仮説には存在しなかった新しい変数が含まれています。この「おいしい」や「後味がよい」といった変数は長方形で表されていますが、これはこれらの変数が実際に観測されたものであることを表しています。これらは観測変数とよばれ、調査で実際に質問する項目となります。
一方、仮説で登場した「味の好み」は楕円形で表されていますが、これは潜在変数とよばれ、実際に観測されない(できない)、もしくは直接正確に観測することができない変数を示します。これは因子分析の因子に相当し、この図で示した4つの観測変数「おいしい」「後味が良い」「飲み飽きない」「飲みやすい」に共通する情報を示します。味が好みであると感じた人ほど、「おいしい」「後味がよい」「飲み飽きない」「飲みやすい」と答えるはず、という仮説がこの部分になり、逆に読めば、「おいしくて」「後味がよくて」「飲み飽きず」「飲みやすい」と答えた人ほど頭の中でも(直接は測定できないが)「味が好み」と感じているだろう、ということを示します。
他方、観測変数をよく見ると、それぞれ1つずつ小さい楕円からパスを受けています。この小さな楕円は潜在変数の一種ですが、観測変数から共通性を除いた独自の成分と測定誤差の両方を含んだものを示しており、ここではまとめて「誤差」と呼びます。つまり、それぞれの観測変数は、潜在変数「味の好み」と「誤差」によって説明できる、というわけです。
調査では多くの場合、測定誤差が存在します。似た質問同士は同じように回答してもらうことができていれば測定誤差は小さく、逆に一貫性が低い場合は測定誤差が大きくなります。本当に知りたいことは「頭の中で感じた何か」ですが、その時々によって回答にブレが生じます。このブレを回避するには、同じ質問を何度も繰り返せばいいのですが、1つの調査の中に同じ調査項目をいれると順序効果が生じるなど、前の設問に影響を受け、一貫性が一部分だけ必要以上に高くなるような不都合が起こります。そのため、少しずつ似た調査項目を用意して、本当にその人が感じている答えを抽出するための仕組みが、この潜在変数という考え方になります。主な目的は測定誤差を分離することになります。共分散構造分析では、このように直接正しく観測することが難しい変数を観測できる変数から推定する、という因子分析に似た分析をモデルに組み入れることができます。
2-4. まとめ
このように、共分散構造分析の多重指標モデルでは、複数の因子分析や重回帰分析を織り交ぜたようなモデルを、1つにまとめて分析することができるのです。因子分析の結果をさらに回帰分析にかけるというようなことを繰り返すと、誤差が蓄積して分析全体の精度が落ちるとともに、モデル全体での誤差を明らかにすることができません。一方、共分散構造分析ではモデル全体を丸ごと1度に分析することができ、推定精度が高まり、その上データとモデルの適合の程度を評価することもできるのです。
以上から、共分散構造分析の多重指標モデルを利用して分析を行うと下記のようなメリットがあることが分かりました。
- 潜在変数を扱うことで、直接観測しづらい変数も測定できる
- 変数と変数の関係性の強さを数値化できる
- パスの始点となる変数の説明力を知ることができる
- データとモデルの当てはまりの程度を評価できる
2-5. 分析実例
それでは、実際に今回の課題に対する答えを出すべく分析を行った結果をご紹介します。(当社が2003年9月に行った自主調査の結果を利用)
ダイエット飲料の魅力についてのモデルを検証するために、実際の調査では4つの代表的なダイエット飲料について質問をしました。
まずはCMの評価については考えない仮説1を検証しましょう。
パス図は図5に表されています。ここでは、「味の好み」と「ダイエット」の間に相関があることを仮定して共変動を表す両方向矢印を引いています。
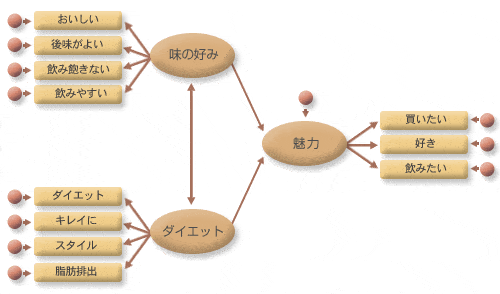
図5 仮説1のパス図
図5のようなモデルを仮定して共分散構造分析を行った結果が図6に表されています。
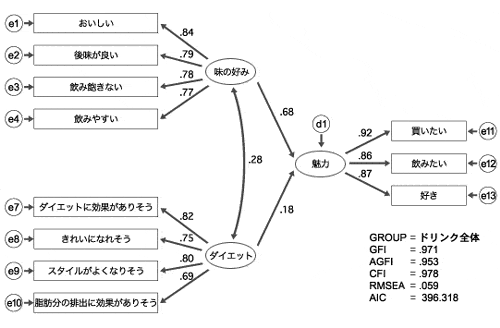
図6 仮説1の共分散構造分析
図6では分析結果としてパス係数が出力されていますが、楕円で表された因子間の関係に注目すると、「味の好み」因子と「魅力」因子間の結びつきは0.68であるのに対して、「ダイエット効果」因子と「魅力」因子間の結びつきは0.18に留まっていることがわかります。これは、ダイエット機能性飲料の魅力を決定する要因として、「味の好み」のほうが「ダイエット機能」よりも影響力が強いということを表しています。モデルの当てはまりの指標も悪くありません。
この基本モデルは、全てのブランドについてパス係数が同じであると仮定しましたが、この仮定を緩めてブランドごとで違ったパス係数を持つ(例えば、ブランドAの場合には「ダイエット因子」が「魅力」を説明する割合が高いなど)ことを許すモデルと比較した結果、モデルの適合度は上がりませんでした。よって、このモデルで考える場合にはブランドごとに評価の仕方の差異はないといえます。
それでは次にCMの評価をモデルに組み込こんで、仮説2に対する分析を行いましょう。モデルと分析結果を図7に示します。
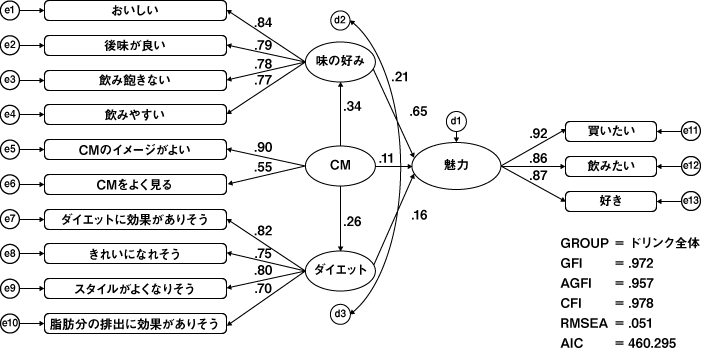
図7 仮説2の共分散構造分析
この結果から、CMに対する評価が高い人は味の好みとダイエット効果の双方の評価が高く、味の好みとダイエット感の評価が高い人は商品が魅力的とも答えているようです。つまり、「CMに対する評価が高い人は味の好みを高く評価するため、魅力の評価も高い」「CM評価が高い人はダイエット効果も高く評価するため、魅力の評価も高い」という間接的な効果があることがわかります。これに加えて、わずかですが、CM効果が高い人は直接、商品が魅力的と答えてもいるので、結局、総合的にこの場合には、CM効果が高い人は商品を魅力的だと答えるという、総合的な関係があることがわかります。
これは、図8に示す因子間相関モデルで見ることがきます。
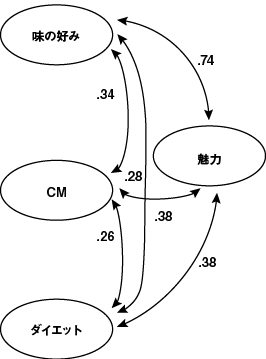
図8 仮説2の因子間相関モデル
このモデルでは、全てのブランドについてパス係数が同じであるという仮定をおきましたが、次に仮説3を検証するためにパス係数がブランドごとに異なるという制約をおいて分析を行います。結果のブランドごとのパス係数は下記のグラフに表されています(図9)。
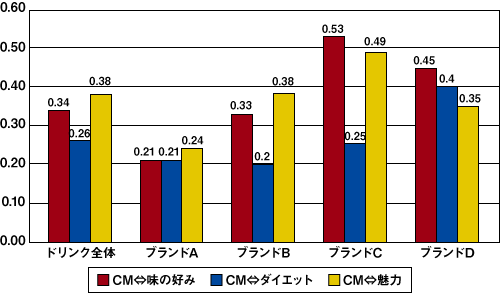
図9 ブランドごとのパス係数
このグラフから、例えば、ブランドCのCM評価が高い人は味の好みが高いものの、ダイエット効果はあまり高くなく、一方で、ブランドDのCM効果が高い人は味の好み・ダイエット効果の両方の評価が高いと読み取ることができます。
今回は3つの仮説を扱っていきましたが、モデルを多少変化させたり制約を強めたりをしていく中で、さまざまな発見ができることも共分散構造分析の大きな魅力の一つです。
また、今回は紹介できませんでしたが、応用として平均構造の分析などを行えば、ブランドごとのCM評価スコアや魅力度スコアの平均値を算出することも可能です。
3. 共分散構造分析を行う際の注意点
共分散構造分析では、見えない変数(潜在変数・因子)をモデルに取り入れることが可能ですが、このような因子をどのように設定していくべきかというのは、難しい問題となります。また、比較的自由に仮説モデルを作成し、検証をしていくことができますが、このようなモデルはパス図とアイデアを相互に翻訳しながら作成していかなくてはなりません。その上で、結果を見てそれを解釈し、仮説モデルに修正を加えていくという作業を正しく行っていくことは容易なことではないのです。
また、調査の運用という面に目を向ければ、生活者ベースの言葉を用いた精緻な選択肢を抽出したり、定性的にみて共分散構造分析の結果を因果にまでつなげて解釈し、その後の実験的な調査・分析に発展させたりするために、評価グリッド法®などの定性調査を適宜行い、仮説が耐えるかどうか各段階で正確な判断を行っていける総合的な調査・分析力が必要となります。
よって、共分散構造分析を行う際には、分析者がモデル作成・モデル解釈において優れた仮説構築力・洞察力・センスを持っている必要性があり、さらに統計的知識も必要となります。当社は従来の多変量解析手法やこの共分散構造分析における非常に多くの経験をもって分析を行っています。
4. 共分散構造分析(SEM)のまとめ
共分散構造分析では、市場や生活者にまつわる複雑な仮説やロジックを、パス図によってシンプルにモデル化し、モデル内での関係性のつながりを見て検証することができます。
さらにモデル構築の自由度が高く、今までは容易に分析することが難しかったモデルでも分析にかけることができるとともに、仮説構築・結果検証の試行錯誤を繰り返す中からさまざまな示唆を得ることが可能です。
今回紹介したものは共分散構造分析の中でも多重指標モデルとよばれるものに限定しており、共分散構造分析が持つ自由なモデル構築は今回紹介したものに留まりません。このような自由なモデル構築力と、結果から引き出されるアウトプットにはこれからもさまざまな可能性があります。共分散構造分析のマーケティングにおける応用範囲はさらに広がってきており、今までの多変量解析では得ることのできなかった多くの示唆を把握できるようになります。








